Recently, I have covered how to install wget in Linux with a few simple steps. So, many viewers requested how do we implement these in the practical world.
Today, we cover 10 wget most used command in Linux. But if you directly jump to these posts or don’t know what we are talking about right now.
So for you, wget is a non-interactive network downloader that is used to download files from the web over HTTP, HTTPS, and FTP protocol even though the user is not logged in.
Let’s Begin
Before jumping ahead for those who are directly reading these post. First, check whether wget is installed correctly in your system or not by typing the following command in your Linux terminal.
$ wget -VIf it outputs the version information, then you good to go or get a message something like command is not found; make sure to read our recent post on installing wget in all major Linux distribution and then continuing from here.
Syntax
$ wget [OPTION] [URL]1. Download the contents of an URL to a File
To download webpages of any site over the internet. Simply, write it URL with wget, and it will download and save in the current location.
$ wget https://www.gnu.org/software/wget/
$ ls
index.html2. Single file download
To download any files over the web, type the following command in your Linux terminal.
$ wget https://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gzTo download a file in the background and access your terminal without waiting for the file to be downloaded.
$ wget -b https://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz
Continuing in background, pid 37170.
Output will be written to ‘wget-log’.-b: These parameters inform wget to download the file in the background and let the user access the terminal. It could be very helpful if you were downloading ISO file, which most probably bigger in file size.
3. Download the files with different location
To download files with a different location, simply pass the option -o with wget and specify the location you want to have your file after download.
$ wget https://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz -O /home/trendoceans/Documents/wget.tar.gz4. Download a single web page and all its resources
If you want to have all files (scripts, stylesheet, images, etc.) of a single web page and all its resources with 5-second intervals between each connection.
$ wget --page-requisites --convert-links --wait=3 https://www.gnu.org/software/wget/Make sure sometimes downloading files using this way can be useless because most of the websites today restrict such action using robots.txt file.
If you don’t know about the robots.txt file, make sure to read google blog post on Introduction to robots.txt.
5. Download a file from an HTTP server with authentication
Downloading files without any authentication is easier using wget. But to download files using authentication is no more than a piece of cake.
$ wget --user=username --password=password https://example.com–user: This option specify user username to access restricted area of the web page.
–password: This option is use to authenticate user with the user username provided in –user.
In the above example, I have not mentioned any specific website because of privacy issues. But you can have access to your FTP server using this method.
6. Limit the download speed and the number of connection retries.
A single file is okay to download without any restriction. But it can be a headache to leave a bunch of giant files to download in the background. It can reduce your bandwidth, and yes, you face low speed while browsing over the internet.
$ wget --limit-rate=100k --tries=100 https://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz–limit-rate: Specify the amount of speed is allowed while downloading the file. In my case, I specified the speed cannot reach more than the 100k while downloading.
–tries: It is an amount of attempt to take while the connection is lost when the file is downloading from the server.
These are beneficial option while downloading a files which is very large and takes more than 30 minutes to download based on your internet connection speed.
7. Continue an incomplete download
Suppose you enter into a situation where the file size is more than 1024 to 2048GB, and it took several minutes to download the file.
Because of this, you are facing low speed while surfing on the webpage, and there is an urgency to have your actual speed back.
Don’t be said to cancel your download file. Simply press Ctrl+z and continue your download file, just passing simple -c option when you are done with your work. It will continue where it is left last time.
$ wget -c https://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz8. Download all URLs stored in a text file
Suppose you have a bunch of links of files or web pages that you wish to download without repeating the same line of command repeatedly.
Then yes, there is a way to automate these processes behind you and do the rest of the other works while your files are downloading behind you.
Before downloading, make sure to have your whole link in a text file and save it. And also, create a directory where all files are going to be downloaded.
$ wget -P path/to/directory -i listofurl.txt-P: Specify your location to a directory where your wish to have your whole file to be downloaded.
-i: Specify your text file where you have saved your whole list of links of files and web pages.
If for any reason you are facing any difficulty while downloading files using this way, be free to ask in the comment section.
9. Check file size
Sometimes in the browser, while downloading a file, it cannot display the file’s total size for any reason.
Sometimes it can be trouble for you and your data if you have limited data because you do not know what will be the size of the file.
To check the size of the file, pass the following command in your terminal.
$ wget --spider https://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz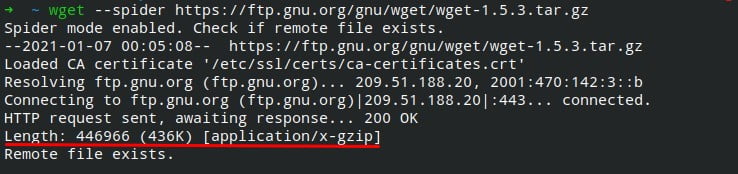
10. Download file recursively
If you are attempting to download a file, but for any reason, it is failing. Then you can download it using recursively. Most of the time, this solves the problem.
$ wget -r [URL]Conclusion
Today I try to cover almost all important topics in wget. For any reason, anything is left. Just let me know in the comment section.
The -b parameters is also very useful as it starts the process in the background. Very useful, for example, when downloading the .ISO files for a new version of a Linux Distro or any other large file.
True