Grep stands for (Global Regular Expression Print) is a Linux command-line utility to perform essential regular expressions in a file.
Finding strings and patterns from the file and streaming the output type of operation can be performed using the grep command.
Grep can be piped with other commands. For example, you can pipe cat and grep together to search for strings from files and display them on the screen.
Today, you will learn to use the grep command with advanced examples.
Searching for String
To perform the search operation, I have created a sample file with the name “file.txt”. Below is the content inside that file.
Hello, TRENDOCEANS! Reader
Hope you are doing great.
We have generated this file to demonstrate
use of the grep command
If you have any questions or queries, please comment down.The above paragraph has “you” repeated multiple times. You can use the "-i" option to perform a search operation on this file to find all the statements containing the “you” keyword, as shown below.
$ grep -i "you" file.txt
Two statements came in the output containing the “you” keyword in them.
Note that when grep, by default, performs a case-insensitive search operation. If you type lowercase “you” or capital “YOU” both are equally handled by grep command, as shown below.

This same operation can be done by piping the grep command with the cat command, as shown below.
$ cat file.txt | grep you
Count the Number of Matches
We can also output the number of times they are repeated, as shown below, by extracting matched strings.
$ grep -c "you" file.txt
2In this case, grep considers case-sensitive, meaning the string “you” and “YOU” will be treated differently.
Recursively Grep all Directories and Subdirectories to find string
When you want to find your search pattern or keywords recursively through a particular directory or subdirectoriores, then use the below command, which will recursively search your string through the directory.
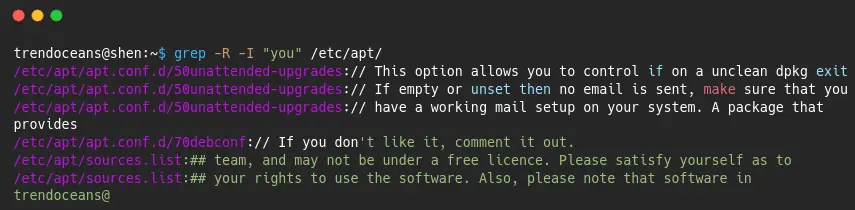
$ grep -R "string" /path/As you know string “you” hold in file.txt, and I’m curious to know is there “you” strings has been used in “/etc/apt” directory, so let’s find it out by invoking the below command:
$ grep -R "you" /etc/aptThe below output made us clear that “you” or related words, are used in multiple files.
The advantage of using -R parameters is that it even looks into symbolic files. If you don’t want to include symbolic files, then you can use -r, which will perform the same work as -R, but it will ignore searching for strings in symbolic files.
$ grep -r "search-string" /path/ Show only matching keywords
While running the above I command, I found it also prints the other words, which includes our search string like “your” and “yourself”, which doesn’t make sense.
If you want grep to focus only on the complete “you” string, then you should use -w or — force pattern to match only whole words option.
$ grep -Rw you /etc/apt/The below output clearly show it’s match only “you”

Output the only matching strings file names
Do you have multiple files that contain some specific string? You can output the files that share the common string using the below command.
$ grep -l "you" *
Above, you can see I have replicated “file.txt” content to “file1.txt” and “file2.txt” and will perform searching them based on “you” keywords to do that “-l” option is being used. If you notice, instead of my file containing matches, grep is also trying to find it in the nested directory.
We were using the “*” symbol while executing the command. If you are sure about your files containing the same file extension, then replace “*” with “*.txt” it will only search for files with the txt extension, as shown below.
$ grep -l "you" *.txt
I recommended approaching this method instead of searching matches recursively in the nested directory, which also strains your system memory.
Show Matches Line Number
Finding matches is helpful, but you have to edit and find that line to modify that string after that. In grep, you can use “-n” option to display a line with respect to matched strings, as shown below.
$ grep -n "you" file.txt 
Add the number of lines after or before displaying the string
There might be a case when you are not able to get context about highlighted strings, or else you want to send output to someone who can easily understand what you mean to say. Then you should take advantage of -A, or –after-context=NUM, which will show the number of lines after filtering your result like in the below image:
$ grep -A1 -n 'you' file.txt Intentionally added -n parameters so you can understand what exactly happended.

Without using the -A parameter, you will get the below result:

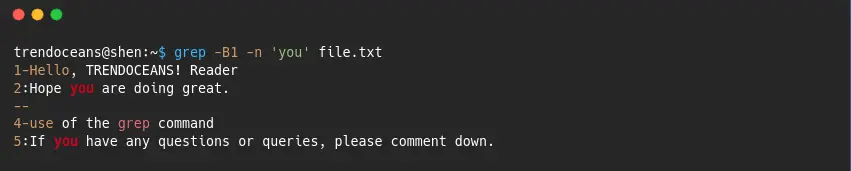
Alternatively you can use -B or –before-context=NUM, which will add number of line before displaying highlighted string, like the below image
Inverting the Pattern Match
If you are focusing on sentences, which should ignore specific keywords or search strings from the file, then you should use -v or –invert-match, which will inverse the matching string and print the output.
For example, if you want to print output without the “you” string, then you should run the below code:
$ grep -v "you" file.txt 
Troubleshoot: grep is not highlighting a matched string
While some of the users may complain that they are not able to view highlighted strings or words as color output, yes, you might face this issue if your system’s ~/.bashrc file is missing this text “alias grep=’grep –color=auto'”.
So make sure to add the following line to your ~/.bashrc file, which will print the filtered output as a colored one.
You should note one more thing that you will not find the coloured output if you pipe the output with some kind of pager like less or more.
Conclusion
Grep is a handy and helpful command that is able to find a single string from a thousand words with the help of regular expressions.