It is very common for Linux administrators to deal with a large number of files where they tackle a large amount of data, and from that junk of that data, he/she needs to curate something meaningful.
As you know, it’s not possible for an individual to sort out and remove duplicate lines from the file one by one, and literally, it will be very tedious work to do, so to rescue this, you have a special tool called "sort" and "uniq" in Linux, and from the name itself, you have realized what the purpose of this tool is. Apart from that, you will also learn how to use the awk command to find duplicate lines.
So let me show you how to implement sort and uniq to remove repetition from a text file that I have specially created for you.
What does a duplicate sample file look like
I have added multiple operating system names in a repetitive order, so you can easily find out the difference when I apply the commands to remove duplicate content from the “duplicate_sample” text file.
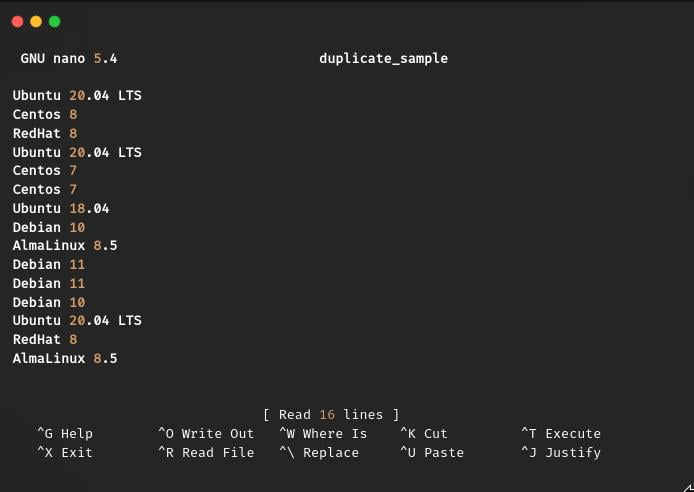
This demo file may not be a succinct example, but it can give a substantial amount of knowledge on how to work with the sort and uniq commands to delete duplicate text.
How to find the most repeated lines
From the above file, you can easily tell me Ubuntu 20.04 LTS is occurring 3 times. What to do if you have a large set of data? It is not possible for you and me to count manually, so in this case, you can easily pass the below command on your terminal screen:
$ sort -nr duplicate_sample | uniq -c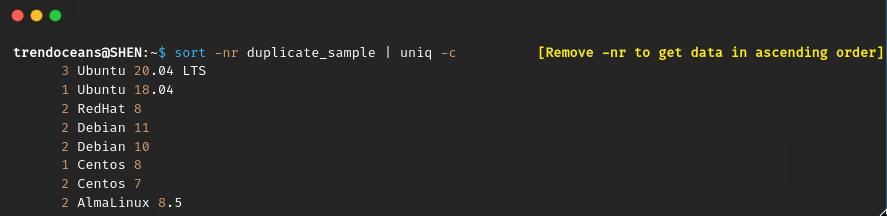
Remove duplicate lines using sort and uniq commands
To remove duplicate lines from the text, you can run the below command. Before that, make sure to replace the duplicate_sample file with an actual name.
$ sort duplicate_sample | uniq
OR
$ sort -u duplicate_sampleThe first command and the second command can both do the same work. In the first method, you have to first sort out your file data, and after that, you have to implement the uniq command on the sorted input file using a pipe.
You may be thinking I’m using the uniq command after the sort command, right? The reason is simple: a uniq command cannot delete a line that is adjacent to the duplicate line.
In a simple way, duplicate line can be anywhere, so the first sort command finds the same piece of content and pile-ups after that uniq command simply remove all the piles of duplicate content at once.
As per the manual sort and uniq command has a specific task to perform
- sort: command is used to sort lines of text files
- uniq: command is used to remove or omit lines of text files.
The simpler version of the first command is to use the -u or –unique options to remove or omit duplicates from a text.
$ sort -u duplicate_sample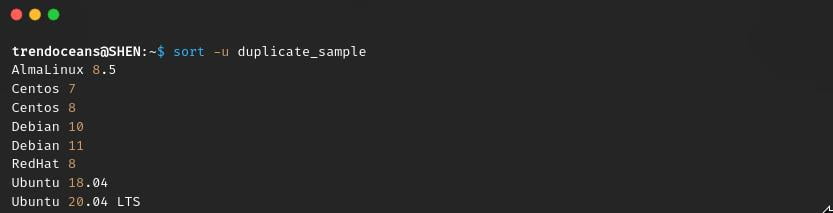
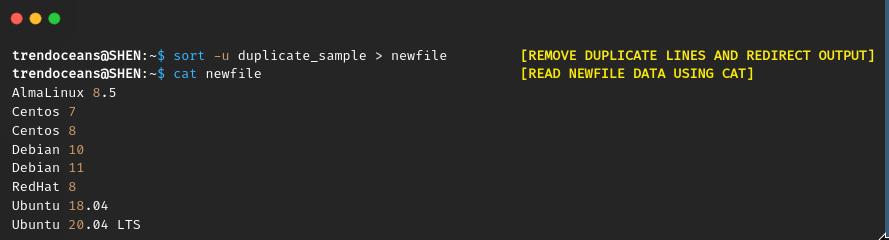
And when you have finished sorting, simply redirect the output to create a new file.
$ sort -u duplicate_sample > newfile
OR
$ sort duplicate_sample | uniq > newfileAfter invoking the above command, you will not find the output on the screen. To view the output, pass the newly created file name similar to the below image.
Remove duplicate lines using awk command
The above method is simple enough. If you are looking for a more complex command to remove duplicate lines from a file, then you can use the awk command.
After the use of the sort and uniq commands, let’s run the awk command to remove duplicate lines from the duplicate_sample that we have created above.
$ awk '!seen[$0]++' duplicate_sample- !seen[$0]++:- seen is an arbitrary user-defined array name, and [$0] is an array or current line if it is an empty or blank line then it will print false, ! negation will turn the whole expression to true, and ++ increment will get extended if the $0 data get matched with $1…$n, and it will not print out the duplicate data to screen.
Here you will not find the output in a sorted manner, but it will eliminate duplicate lines from the text.
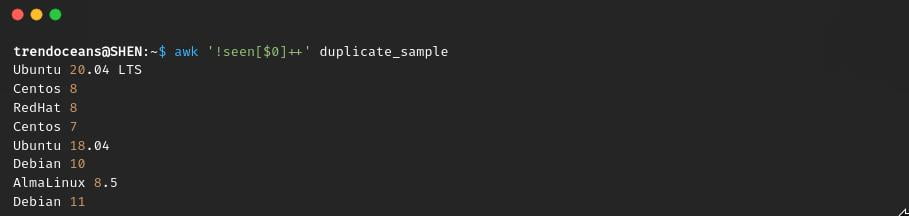
And if you want to save these changes to the same file, run the below command.
$ awk '!seen[$0]++' duplicate_sample > newfile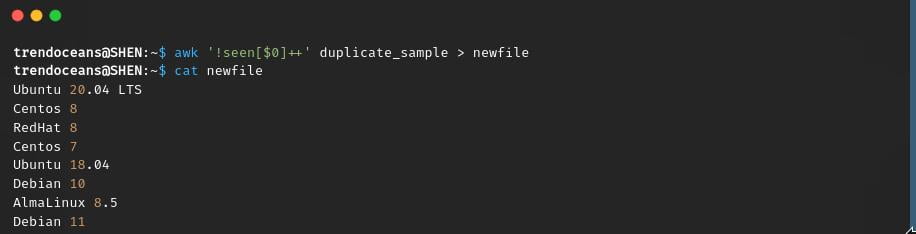
You can also save data directly to the original file, but I would say unless and until you are not sure about the output, then don’t append data to the original file. If you are sure, then run the below command:
$ awk -i inplace '!seen[$0]++' duplicate_sampleTL; DR Version of How to Remove the Duplicate Line from the File
Find the most occurring or repeated lines from the text file on Linux:
$ sort -nr [FILE-NAME]| uniq -cRemove the most occurring or repeated lines from the text file using sort and uniq on Linux:
$ sort [FILE-NAME] | uniq
OR
$ sort -u [FILE-NAME]Save the output after removing the duplicated line from the text file:
$ sort -u [FILE-NAME] > [NEW-FILE-NAME]
OR
$ sort [FILE-NAME] | uniq > [NEW-FILE-NAME]Remove the duplicate lines from the text file using the awk command on Linux:
$ awk '!seen[$0]++' [FILE-NAME]Save the output after removing the duplicate line using the awk command on Linux, or if you want to append new changes directly to the original file, then use the second command:
$ awk '!seen[$0]++' [FILE-NAME] > [NEW-FILE-NAME]
OR
$ awk -i inplace '!seen[$0]++' [FILE-NAME]Michael DeBusk shared with us a command which can remove the duplicate pieces of content without touching the original order of your file.
$ nl -w1 [FILE-NAME] | sort -k2 | uniq -f1 | sort -n | cut -f2-Wrap up
That’s all!
From this article, you have learned how to remove or delete duplicated lines from the text file using sort, uniq and awk commands.
If you want to learn more about sort, uniq, and awk commands use manual "man sort", "man uniq", and "man awk".
The downside is that it leaves you with a sorted file. If that’s OK with you, no problem. But if you want the lines in their original order, this works:
nl -w1 bar.txt | sort -k2 | uniq -f1 | sort -n | cut -f2-
We have added your command in article.
Thanks for sharing!